
”机器学习 K-means 聚类算法“ 的搜索结果

python实现机器学习K-means聚类算法.zip对数据进行聚类并绘图。原理 K-means算法属于八大经典的机器学习算法中的其中一种,是一种无监督的聚类算法。其中无监督是机器学习领域中一个专业名词,和有监督是相对的,...
K-Means算法又称K均值算法,属于聚类(clustering)算法的一种,是应用最广泛的聚类算法之一。所谓聚类,即根据相似性原则,将具有较高相似度的数据对象划分至同一类簇,将具有较高相异度的数据对象划分至不同类簇。...
(带注释)基于K-means聚类算法的图像区域分割.zip,MATLAB实现,详情可以参考:https://blog.csdn.net/didi_ya/article/details/115376184
实验五 K-Means聚类算法.ipynb
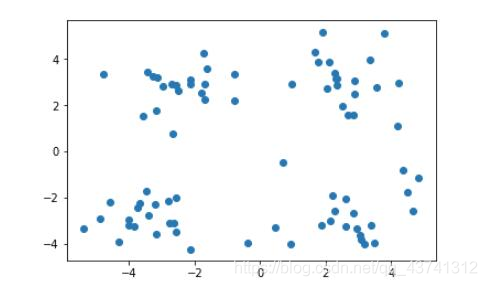
– K-means(k均值聚类) 2、主成分分析 应用PCA实现特征的降维 ·定义:高维数据转化为低维数据的过程,在此过程中可能会舍弃原有数据、创造新的变量 ·作用:是数据维散压缩,尽可能降低原数据的维数(复杂度),...
K-means聚类PPT,讲课实用课件。共包括算法原理、算法流程、实例讲解、应用场景、算法总结、改进算法几个内容。
K-Means是聚类算法的一种,通过距离来判断数据点间的相似度并据此对数据进行聚类。 1 聚类算法 科学计算中的聚类方法 方法名称 参数 可伸缩性 用例 几何形状(使用的指标) K-Means number of ...
本项目使用python实现机器学习K-means聚类算法,对数据进行聚类并绘图。 数据使用了boss直聘北京市大数据的数据,K-means的两个特征值选取的是每个岗位的最低薪资和最高薪资 初始质心选取了3个,即k=3、
1.1 k-means算法的步骤 假设k=3,要分3个群体 随机在数据当中抽取3个样本,当作三个类别的中心点(k1,k2,k3) 计算其余的点分别到这3个中心点的距离,每一个样本有3个距离(a,b,c),从中选出距离最近的一个点...

这是一个MATLAB系列视频,共围绕30个计算机视觉和机器学习的实战项目展开。十分适合作为课程作业或是...06_基于K-means聚类算法的图像分割,适合本科或部分研究生课程设计。 涉及到机器学习相关内容。 #2021#图像分割#
matlab实现k均值聚类算法,以1000个五组随机样本为例,绘制出聚类中心点并分类,可计算出聚类精度和NMI指标结果。
机器学习课程作业_基于matlab实现K-means聚类算法并应用于压缩图像(matlab完整源码).zip 机器学习课程作业_基于matlab实现K-means聚类算法并应用于压缩图像(matlab完整源码).zip 机器学习课程作业_基于matlab实现K-...

代码,介绍,数据源,效果展示
如果你想讲解关于k-means算法,却没有相应的ppt,那你来对了。我在一次面试的过程中也遇到了相似的情况,我精心做了一份关于k-means算法的ppt。如果你需要可以使用,但是使用的时候主要不要照抄哦。自己适度的改一改...
k-means聚类分析西瓜的密度与含糖率 第一部分:数据集 X表示二维矩阵数据,表示西瓜密度和含糖率 总共30行,每行两列数据 第一列表示西瓜密度:x1 第二列表示西瓜含糖率:x2 from sklearn.cluster import Birch # 从...
机器学习算法示例 从零开始使用scikit-learn进行K-Means聚类 技术: Python 3; Jupyter笔记本。 执照 该项目根据MIT许可条款获得许可。
主要的方法就是,将数据存储在kd树这种空间数据结构中,树的思想...最后感谢Tapas Kanungo等的论文《An Efficient k-Means Clustering Algorithm:Analysis and Implementation》提供的算法思路和证明。实现代码见附件。
“聚类算法”是无监督学习中经常使用的算法,因此今天我们来聊聊两种典型聚类算法:K-means聚类算法及DBSCAN聚类算法。 通常来说,聚类是将数据集中的样本划分为若干个不相交的子集,每个子集称为一个簇(cluster)...
K-Means 算法是一种无监督的聚类算法,其核心思想是:对于给定的样本集,按照样本点之间的距离大小,将样本集划分为K个簇,并让簇内的点尽量紧凑,簇间的点尽量分开算法流程图如下:K-Means算法流程如图,以为例:...
本节用Python实现K-Means算法,对未...k-means算法,也被称为k-平均或k-均值算法,是一种使用最广泛的聚类算法。根据个体到每个类中心的距离进行划分,而类中心用类中所有个体的均值来度量。 思路及步骤: 随机或按某
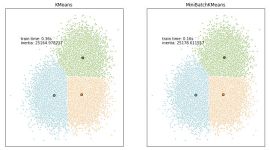
k-means聚类算法及matlab代码适用于Coursera机器学习的Python代码 此仓库为Andrew NG教授的Coursera机器学习课程提供了基于python的解决方案。 解决方案模仿Coursera提供的MATLAB / Octave代码。 scikit-learn模块为...
聚类是一个将数据集中在某些方面相似的数据成员...K-means算法是典型的基于距离(欧式距离、曼哈顿距离)的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。,x_n)和y= (y_1,y_2,…
聚类分析是一种典型的无监督学习, 用于对未知类别的样本进行划分,将它们按照一定的规则划分成若干个类族,把相似(距高相近)的样本聚在同一个类簇中, 把不相似的样本分为不同类簇,从而揭示样本之间内在的性质以及...
推荐文章
- confluence搭建部署_ata confluence-程序员宅基地
- SpringCloud与SpringBoot版本对应关系_springboot 2.1.1 对于的cloud-程序员宅基地
- 如何恢复硬盘数据?简单解决问题_磁盘恢复 csdn-程序员宅基地
- 苹果手机测试网络速度的软件,App Store 上的“网速测试大师-测网速首选”-程序员宅基地
- 教了一年少儿编程,说说感想和体验-程序员宅基地
- 22东华大学计算机专硕854考研上岸实录-程序员宅基地
- 如何用《玉树芝兰》入门数据科学?-程序员宅基地
- macOS使用brew包管理器_brew清理缓存-程序员宅基地
- 【echarts没有刷新】用按钮切换echarts图表的时候,该消失的图表还在,加个key属性就解决了_echarts 怎么加key值-程序员宅基地
- 常用机器学习的模型和算法_常见机器学习模型算法整理和对应超参数表格整理-程序员宅基地